
Extra material: Optimal Growth Portfolios with Risk Aversion#
Among the reasons why Kelly was neglected by investors were high profile critiques by the most famous economist of the 20th Century, Paul Samuelson. Samuelson objected on several grounds, among them is a lack of risk aversion that results in large bets and risky short term behavior, and that Kelly’s result is applicable to only one of many utility functions that describe investor preferences. The controversy didn’t end there, however, as other academic economists, including Harry Markowitz, and practitioners found ways to adapt the Kelly criterion to investment funds.
This notebook presents solutions to Kelly’s problem for optimal growth portfolios using exponential cones. A significant feature of this notebook is the the inclusion of a risk constraints recently proposed by Boyd and coworkers. These notes are based on recent papers such as Cajas (2021), Busseti, Ryu and Boyd (2016), Fu, Narasimhan, and Boyd (2017). Additional bibliographic notes are provided at the end of the notebook.
import sys, os
if 'google.colab' in sys.modules:
%pip install idaes-pse --pre >/dev/null 2>/dev/null
!idaes get-extensions --to ./bin
os.environ['PATH'] += ':bin'
solver = "ipopt"
else:
solver = "mosek_direct"
import pyomo.kernel as pmo
import pyomo.environ as pyo
SOLVER = pmo.SolverFactory(solver)
assert SOLVER.available(), f"Solver {solver} is not available."
Financial Data#
We begin by reading historical prices for a selected set of trading symbols using yfinance.
While it would be interesting to include an international selection of financial indices and assets, differences in trading and bank holidays would involve more elaborate coding. For that reason, the following cell has been restricted to indices and assets trading in U.S. markets.
# run this cell to install yfinance
!pip install yfinance --upgrade -q
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import datetime
import yfinance as yf
# symbols as used by Yahoo Finance
symbols = {
# selected indices
"^GSPC": "S&P 500",
"^IXIC": "Nasdaq",
"^DJI": "Dow Jones Industrial",
"^RUT": "Russell 2000",
# selected stocks
"AXP": "American Express",
"AMGN": "Amgen",
"AAPL": "Apple",
"BA": "Boeing",
"CAT": "Caterpillar",
"CVX": "Chevron",
"JPM": "JPMorgan Chase",
"MCD": "McDonald's",
"MMM": "3 M",
"MSFT": "Microsoft",
"PG": "Proctor & Gamble",
"XOM": "ExxonMobil",
}
# years of testing and training data
n_test = 1
n_train = 2
# get today's date
today = datetime.datetime.today().date()
# training data dates
end = today - datetime.timedelta(int(n_test * 365))
start = end - datetime.timedelta(int((n_test + n_train) * 365))
# get training data
S = yf.download(list(symbols.keys()), start=start, end=end)["Adj Close"]
# compute gross returns
R = S / S.shift(1)
R.dropna(inplace=True)
[*********************100%%**********************] 16 of 16 completed
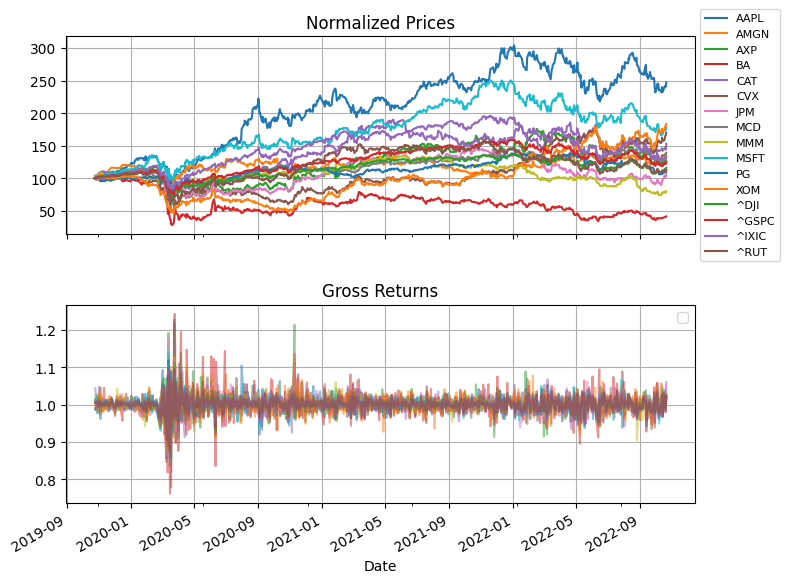
fig, ax = plt.subplots(2, 1, figsize=(8, 6), sharex=True)
S.divide(S.iloc[0] / 100).plot(ax=ax[0], grid=True, title="Normalized Prices")
ax[0].legend(loc="center left", bbox_to_anchor=(1.0, 0.5), prop={"size": 8})
R.plot(ax=ax[1], grid=True, title="Gross Returns", alpha=0.5).legend([])
plt.tight_layout()
plt.show()
Portfolio Design for Optimal Growth#
Model#
Here we are examining a set \(N\) of financial assets trading in efficient markets. The historical record consists of a matrix \(R \in \mathbb{R}^{T\times N}\) of gross returns where \(T\) is the number of observations.
The weights \(w_n \geq 0\) for \(n\in N\) denote the fraction of the portfolio invested in asset \(n\). Any portion of the portfolio not invested in traded assets is assumed to have a gross risk-free return \(R_f = 1 + r_f\), where \(r_f\) is the return on a risk-free asset.
Assuming the gross returns are independent and identically distributed random variables, and the historical data set is representative of future returns, the investment model becomes
Note this formulation allows the sum of weights \(\sum_{n\in N} w_n\) to be greater than one. In that case the investor would be investing more than the value of the portfolio in traded assets. In other words the investor would be creating a leveraged portfolio by borrowing money at a rate \(R_f\). To incorporate a constraint on the degree of leveraging, we introduce a constraint
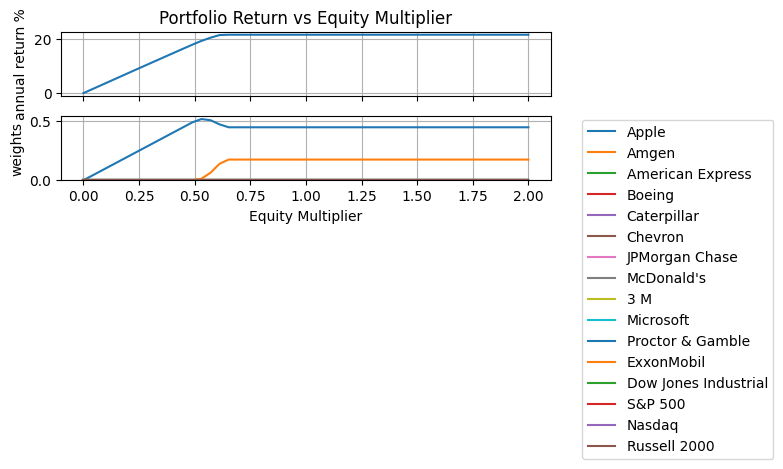
where \(E_M\) is the “equity multiplier.” A value \(E_M \leq 1\) restricts the total investment to be less than or equal to the equity available to the investor. A value \(E_M > 1\) allows the investor to leverage the available equity by borrowing money at a gross rate \(R_f = 1 + r_f\).
Using techniques demonstrated in other examples, this model can be reformulated with exponential cones.
For the risk constrained case, we consider a constraint
where \(\lambda\) is a risk aversion parameter. Assuming the historical returns are equiprobable
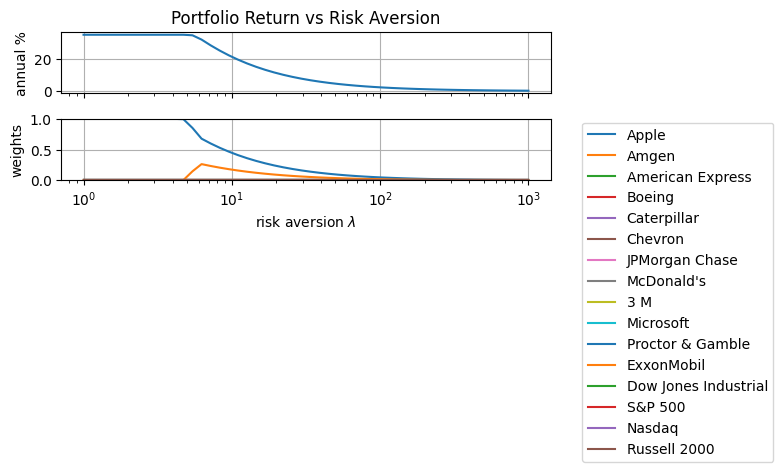
The risk constraint is satisfied for any \(w_n\) if the risk aversion parameter \(\lambda=0\). For any value \(\lambda > 0\) the risk constraint has a feasible solution \(w_n=0\) for all \(n \in N\). Recasting as a sum of exponentials,
Using the \(q_t \leq \log(R_t)\) as used in the examples above, and \(u_t \geq e^{- \lambda q_t}\), we get the risk constrained model optimal log growth.
Given a risk-free rate of return \(R_f\), a maximum equity multiplier \(E_M\), and value \(\lambda \geq 0\) for the risk aversion, risk constrained Kelly portfolio is given the solution to
The following cells demonstrate an implementation of the model using the Pyomo kernel library and Mosek solver.
Pyomo Implementation#
The Pyomo implementation for the risk-constrained Kelly portfolio accepts three parameters, the risk-free gross returns \(R_f\), the maximum equity multiplier, and the risk-aversion parameter.
def kelly_portfolio(R, Rf=1, EM=1, lambd=0):
m = pmo.block()
# return parameters with the model
m.Rf = Rf
m.EM = EM
m.lambd = lambd
# index lists
m.T = R.index
m.N = R.columns
# decision variables
m.q = pmo.variable_dict({t: pmo.variable() for t in m.T})
m.w = pmo.variable_dict({n: pmo.variable(lb=0) for n in m.N})
# objective
m.ElogR = pmo.objective(sum(m.q[t] for t in m.T) / len(m.T), sense=pmo.maximize)
# conic constraints on return
m.R = pmo.expression_dict(
{
t: pmo.expression(Rf + sum(m.w[n] * (R.loc[t, n] - Rf) for n in m.N))
for t in m.T
}
)
m.c = pmo.block_dict(
{t: pmo.conic.primal_exponential.as_domain(m.R[t], 1, m.q[t]) for t in m.T}
)
# risk constraints
m.u = pmo.variable_dict({t: pmo.variable() for t in m.T})
m.u_sum = pmo.constraint(sum(m.u[t] for t in m.T) / len(m.T) <= Rf ** (-lambd))
m.r = pmo.block_dict(
{
t: pmo.conic.primal_exponential.as_domain(m.u[t], 1, -lambd * m.q[t])
for t in m.T
}
)
# equity multiplier constraint
m.w_sum = pmo.constraint(sum(m.w[n] for n in m.N) <= EM)
SOLVER.solve(m)
return m
def kelly_report(m):
s = f"""
Risk Free Return = {100*(np.exp(252*np.log(m.Rf)) - 1):0.2f}
Equity Multiplier Limit = {m.EM:0.5f}
Risk Aversion = {m.lambd:0.5f}
Portfolio
"""
s += "\n".join([f"{n:8s} {symbols[n]:20s} {100*m.w[n]():7.2f} %" for n in m.N])
s += f"""
{'':8s} {'Risk Free':20s} {100*(1 - sum(m.w[n]() for n in R.columns)):7.2f} %
Annualized return = {100*(np.exp(252*m.ElogR()) - 1):0.2f} %
"""
print(s)
df = pd.DataFrame(pd.Series([m.R[t]() for t in m.T]), columns=["Kelly Portfolio"])
df.index = m.T
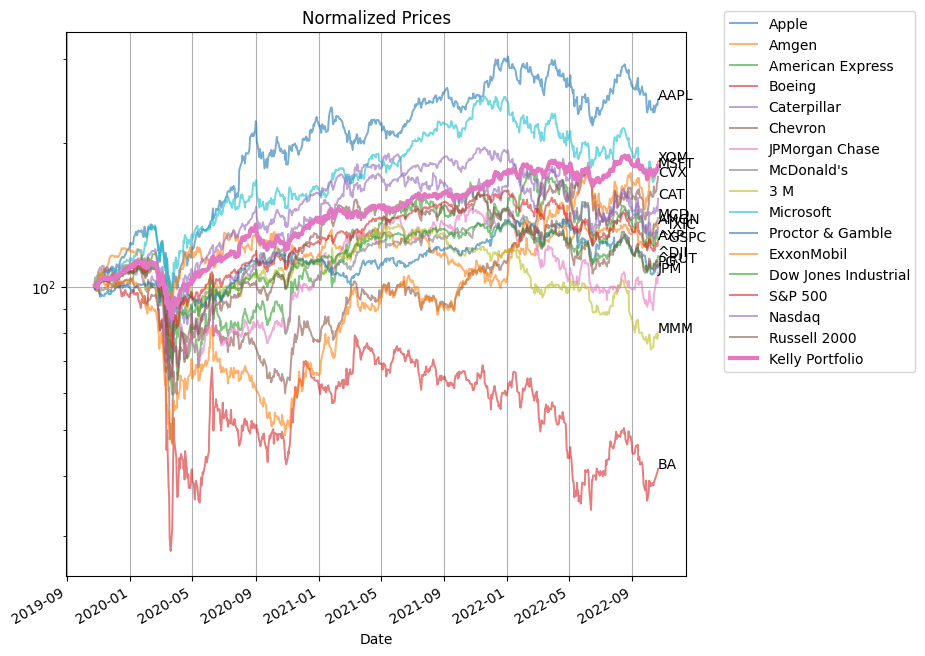
fix, ax = plt.subplots(1, 1, figsize=(8, 8))
S.divide(S.iloc[0] / 100).plot(
ax=ax, logy=True, grid=True, title="Normalized Prices", alpha=0.6, lw=1.4
)
df.cumprod().multiply(100).plot(ax=ax, lw=3, grid=True)
ax.legend(
[symbols[n] for n in m.N] + ["Kelly Portfolio"], bbox_to_anchor=(1.05, 1.05)
)
d = S.index[-1]
print(d, "\n")
for n in m.N:
y = 100 * S[n].iloc[-1] / S[n].iloc[0]
print(f"{n:5} {100 * S[n].iloc[-1] / S[n].iloc[0]:8.6f}")
ax.text(d, y, n)
# parameter values
Rf = Rf = np.exp(np.log(1.0) / 252)
EM = 1
lambd = 10
m = kelly_portfolio(R, Rf, EM, lambd)
kelly_report(m)
Risk Free Return = 0.00
Equity Multiplier Limit = 1.00000
Risk Aversion = 10.00000
Portfolio
AAPL Apple 44.79 %
AMGN Amgen 0.00 %
AXP American Express 0.00 %
BA Boeing 0.00 %
CAT Caterpillar 0.00 %
CVX Chevron 0.00 %
JPM JPMorgan Chase 0.00 %
MCD McDonald's 0.00 %
MMM 3 M 0.00 %
MSFT Microsoft 0.00 %
PG Proctor & Gamble 0.00 %
XOM ExxonMobil 17.49 %
^DJI Dow Jones Industrial 0.00 %
^GSPC S&P 500 0.00 %
^IXIC Nasdaq 0.00 %
^RUT Russell 2000 0.00 %
Risk Free 37.72 %
Annualized return = 21.49 %
2022-10-21 00:00:00
AAPL 247.190366
AMGN 135.564623
AXP 125.480615
BA 41.500638
CAT 152.966799
CVX 170.056351
JPM 107.132849
MCD 139.303171
MMM 80.247408
MSFT 178.071398
PG 110.924581
XOM 183.324833
^DJI 115.955780
^GSPC 124.664067
^IXIC 132.665347
^RUT 112.512189
S.head()
| AAPL | AMGN | AXP | BA | CAT | CVX | JPM | MCD | MMM | MSFT | PG | XOM | ^DJI | ^GSPC | ^IXIC | ^RUT | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Date | ||||||||||||||||
| 2019-10-24 | 59.226212 | 179.793304 | 109.976357 | 340.524902 | 121.859108 | 98.259621 | 110.789543 | 178.749512 | 137.810425 | 134.666946 | 113.046753 | 55.898674 | 26805.529297 | 3010.290039 | 8185.799805 | 1548.489990 |
| 2019-10-25 | 59.955654 | 179.784424 | 111.724091 | 335.860046 | 127.212341 | 99.170517 | 111.675674 | 177.463715 | 141.385712 | 135.427185 | 111.651657 | 56.028133 | 26958.060547 | 3022.550049 | 8243.120117 | 1558.709961 |
| 2019-10-28 | 60.556232 | 181.519867 | 112.026421 | 336.897766 | 127.512772 | 99.011734 | 112.101013 | 174.883026 | 143.913925 | 138.756805 | 111.860023 | 55.534607 | 27090.720703 | 3039.419922 | 8325.990234 | 1571.930054 |
| 2019-10-29 | 59.155693 | 185.043839 | 110.930519 | 344.853729 | 128.668976 | 98.719246 | 112.030106 | 175.649017 | 143.701126 | 137.448059 | 111.968727 | 55.372787 | 27071.460938 | 3036.889893 | 8276.849609 | 1577.069946 |
| 2019-10-30 | 59.148396 | 186.717285 | 111.544601 | 342.017273 | 127.767677 | 97.240089 | 111.409836 | 179.542816 | 143.326614 | 139.160965 | 113.182632 | 54.790260 | 27186.689453 | 3046.770020 | 8303.980469 | 1572.849976 |
Effects of the Risk-Aversion Parameter#
lambd = 10 ** np.linspace(0, 3)
results = [kelly_portfolio(R, Rf=1, EM=1, lambd=_) for _ in lambd]
fig, ax = plt.subplots(2, 1, figsize=(8, 4), sharex=True)
ax[0].semilogx(
[m.lambd for m in results], [100 * (np.exp(252 * m.ElogR()) - 1) for m in results]
)
ax[0].set_title("Portfolio Return vs Risk Aversion")
ax[0].set_ylabel("annual %")
ax[0].grid(True)
ax[1].semilogx(
[m.lambd for m in results], [[m.w[n]() for n in R.columns] for m in results]
)
ax[1].set_ylabel("weights")
ax[1].set_xlabel("risk aversion $\lambda$")
ax[1].legend([symbols[n] for n in m.N], bbox_to_anchor=(1.05, 1.05))
ax[1].grid(True)
ax[1].set_ylim(0, EM)
plt.tight_layout()
plt.show()
Effects of the Equity Multiplier Parameter#
EM = np.linspace(0.0, 2.0)
results = [kelly_portfolio(R, Rf=1, EM=_, lambd=10) for _ in EM]
fig, ax = plt.subplots(2, 1, figsize=(8, 4), sharex=True)
ax[0].plot(
[m.EM for m in results], [100 * (np.exp(252 * m.ElogR()) - 1) for m in results]
)
ax[0].set_title("Portfolio Return vs Equity Multiplier")
ax[0].set_ylabel("annual return %")
ax[0].grid(True)
ax[1].plot([m.EM for m in results], [[m.w[n]() for n in R.columns] for m in results])
ax[1].set_ylabel("weights")
ax[1].set_xlabel("Equity Multiplier")
ax[1].legend([symbols[n] for n in m.N], bbox_to_anchor=(1.05, 1.05))
ax[1].grid(True)
ax[1].set_ylim(
0,
)
plt.tight_layout()
plt.show()
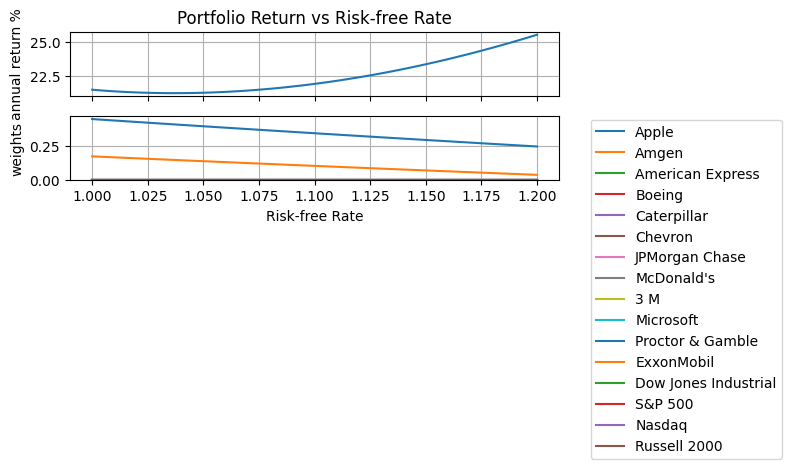
Effect of Risk-free Interest Rate#
Rf = np.exp(np.log(1 + np.linspace(0, 0.20)) / 252)
results = [kelly_portfolio(R, Rf=_, EM=1, lambd=10) for _ in Rf]
fig, ax = plt.subplots(2, 1, figsize=(8, 4), sharex=True)
Rf = np.exp(252 * np.log(np.array([_.Rf for _ in results])))
ax[0].plot(Rf, [100 * (np.exp(252 * m.ElogR()) - 1) for m in results])
ax[0].set_title("Portfolio Return vs Risk-free Rate")
ax[0].set_ylabel("annual return %")
ax[0].grid(True)
ax[1].plot(Rf, [[m.w[n]() for n in R.columns] for m in results])
ax[1].set_ylabel("weights")
ax[1].set_xlabel("Risk-free Rate")
ax[1].legend([symbols[n] for n in m.N], bbox_to_anchor=(1.05, 1.05))
ax[1].grid(True)
ax[1].set_ylim(
0,
)
plt.tight_layout()
plt.show()
Extensions#
The examples cited in this notebook assume knowledge of the probability mass distribution. Recent work by Sun and Boyd (2018) and Hsieh (2022) suggest models for finding investment strategies for cases where the distributions are not perfectly known. They call the “distributional robust Kelly gambling.” A useful extension to this notebook would be to demonstrate a robust solution to one or more of the examples.
Bibliographic Notes#
Thorp, E. O. (2017). A man for all markets: From Las Vegas to wall street, how i beat the dealer and the market. Random House.
Thorp, E. O. (2008). The Kelly criterion in blackjack sports betting, and the stock market. In Handbook of asset and liability management (pp. 385-428). North-Holland. https://www.palmislandtraders.com/econ136/thorpe_kelly_crit.pdf
MacLean, L. C., Thorp, E. O., & Ziemba, W. T. (2010). Good and bad properties of the Kelly criterion. Risk, 20(2), 1. https://www.stat.berkeley.edu/~aldous/157/Papers/Good_Bad_Kelly.pdf
MacLean, L. C., Thorp, E. O., & Ziemba, W. T. (2011). The Kelly capital growth investment criterion: Theory and practice (Vol. 3). world scientific. https://www.worldscientific.com/worldscibooks/10.1142/7598#t=aboutBook
Carta, A., & Conversano, C. (2020). Practical Implementation of the Kelly Criterion: Optimal Growth Rate, Number of Trades, and Rebalancing Frequency for Equity Portfolios. Frontiers in Applied Mathematics and Statistics, 6, 577050. https://www.frontiersin.org/articles/10.3389/fams.2020.577050/full
The utility of conic optimization to solve problems involving log growth is more recent. Here are some representative papers.
Cajas, D. (2021). Kelly Portfolio Optimization: A Disciplined Convex Programming Framework. Available at SSRN 3833617. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3833617
Busseti, E., Ryu, E. K., & Boyd, S. (2016). Risk-constrained Kelly gambling. The Journal of Investing, 25(3), 118-134. https://arxiv.org/pdf/1603.06183.pdf
Fu, A., Narasimhan, B., & Boyd, S. (2017). CVXR: An R package for disciplined convex optimization. arXiv preprint arXiv:1711.07582. https://arxiv.org/abs/1711.07582
Sun, Q., & Boyd, S. (2018). Distributional robust Kelly gambling. arXiv preprint arXiv: 1812.10371. https://web.stanford.edu/~boyd/papers/pdf/robust_kelly.pdf
The recent work by CH Hsieh extends these concepts in important ways for real-world implementation.
Hsieh, C. H. (2022). On Solving Robust Log-Optimal Portfolio: A Supporting Hyperplane Approximation Approach. arXiv preprint arXiv:2202.03858. https://arxiv.org/pdf/2202.03858